CS-151 Labs > Lab 4. My LinkedList
Part 3. Access speeds!
We saw in the warmup that accessing elements in a linked list by
index using get() is very slow comparing to the use of an iterator().
In this part of the lab, we’re going
to experiment to see how the access times
change for different list sizes.
The input files for this part are in texts.zip. If you place the files in a folder texts in the project folder, then your arguments for
the Run Configurations should be similar to texts/Prufrock.txt.
The driver program for this part is in file
IterationTester.java.
This program opens up the text file whose name is given
as a command-line parameter and makes a list of all the different words that appear in the
file. Each time it reads a word it checks whether the wordlist already contains this
word; if not, it adds it to the list. The test is performed by iterating over the wordlist.
The program repeats this
using three different approaches, and prints the number of milliseconds each approach takes.
The first version maintains the list of words as an ArrayList<String>. To see
if a word is already an element of the list, it uses the for loop and w = list.get(i) at each iteration i.
We call this version Array List.
The second version maintains the list of words in MyLinkedList<String> and
uses an iterator to walk through the words of the list. At each step
w = it.next(). We call this version Iterator.
The third version again maintains the list of words as
MyLinkedList<String>, but as with the ArrayList version it uses the loop with w = list.get(i) to look for the word in the list. We saw in the warmup that this
is not very efficient. This version we call Indexing, because it uses access by index to move through the Linked List.
Use the program IterationTester to complete the following table. In your
README.txt file record the times taken by each approach for every test file.
To save you a little time, we have included a start of the table in the sample README file.
Ignore sample values of times in the first row, replace them with your own running times.
File Words Unique Words ArrayList Time Iterator Time Indexing Time
Prufrock.txt 1084 501 45 ms 28 ms 25 ms
IHaveADream.txt 1589 630
EveOfStAgnes.txt 2902 1566
KentuckyDerby.txt 7277 2605
MagnaCarta.txt 17473 2818
Hamlet.txt 32006 7718
Note that the program might run for several minutes on the longer files, so be patient.
Once you have run the program on all the text files and filled out the table, go to Google Sheets and create a new spreadsheet (you can log in with your Oberlin email and password, if you need to). Enter the numbers in spreadsheet like this.
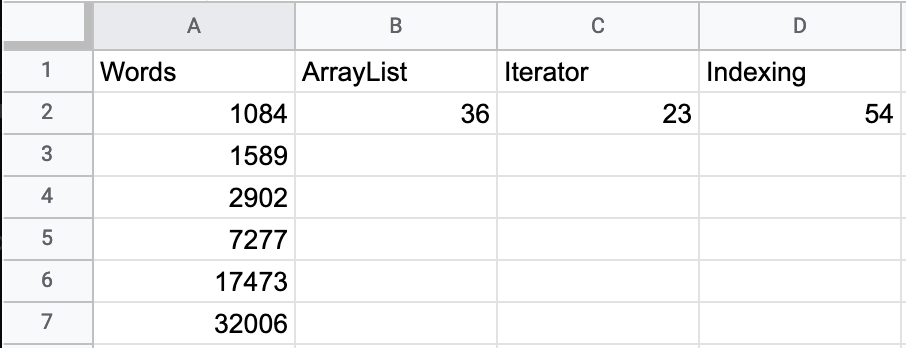
Select the entire table, including the header in row 1, and then from the
Insert menu, select Chart. Under Chart type, select Line chart. This
should create a chart with three lines, one for ArrayList, one for
Iterator, and one for Indexing.
As the number of words increases, the running time increases. The running time taken
by each of the three approaches dows not grow at the same rate. Answer the following
questions in the README file:
- How do the growth rates for
ArrayListandIteratorcompare? - How do the growth rates for
IteratorandIndexingcompare? - If you were tasked with storing data in a list and you needed to sequentially examine elements in the list, which approach would you take and why?
By the way, here are the descriptions of the input files:
Prufrock.txtis “The Love Song of J. Alfred Prufrock” a poem by T.S. EliotIHaveADream.txtis the famous speech given by Dr. Martin Luther King on August 28, 1963EveOfStAgnes.txtis the poem “The Eve of St. Agnes” by John KeatsKentuckyDerby.txtis the short story “The Kentucky Derby is Decadant and Depraved” by Hunter S. ThompsonMagnaCarta.txtis several versions of the Magna CartaHamlet.txtis the play “Hamlet” by William Shakespeare